 |
AFO 133 - Invoer /output profielen
Het startpunt voor alle conversies is AFO 133. In deze AFO dient u aan te geven wat de structuur is van het bestand dat u wenst in te lezen of uit te schrijven. Hiervoor dient u eerst een analyse te maken van de manier waarop de gegevens zijn aangeleverd.
De import/exportmodule kan standaard overweg met verschillende digitale bestandsformaten. Ruwweg kunnen alle bestanden ingedeeld worden in onderstaande varianten.
1.
“Delimited”
Een delimited bestand bevat gegevens die gescheiden zijn door een bepaald scheidingsteken. Meestal zijn er dan meerdere scheidingstekens in gebruik, één voor het scheiden van de onderlinge velden, en één voor het scheiden van de verschillende records.
In het voorbeeld hierboven zien we een Excel blad met daarin bibliografische gegevens. Vanuit Excel (of Access) is het relatief eenvoudig om de gegevens “delimited” (gescheiden) op te slaan.
Een voorbeeld van delimited gegevens (met “;” als delimiter):
Titel; auteur; plaats uitgave; uitgever; etc.
De importmodule behandelt de gegevens als het ware per kolom zoals ze oorspronkelijk in het Excel- of Access bestand waren opgeslagen, waarbij kolom 4 in dit voorbeeld de titel bevat, kolom 3 de auteur, etc.
De enige beperking die de importmodule hierbij heeft is dat iedere kolom een eigen veld vormt. Je kunt niet nog eens per kolom velden uitsplitsen. In de praktijk zie je vaak dat alle auteurs in een veld (kolom dus) gezet worden. Voor een succesvolle import dient iedere auteur naar een eigen veld (in dit geval kolom) verplaatst te worden.
2.
“Tagged”
Een tagged formaat wil zeggen dat ieder veld met gegevens voorzien is van een label waaraan de importmodule kan herkennen om wat voor type gegevens het gaat.
Een puur voorbeeld van een tagged format is:

De eerste twee letters op elke regel geven aan om welk veld het gaat. Dus: TA = taal, TI = titel, DE = descriptor, EX = exemplaargegevens enz. Na de spatie volgt de inhoud van het veld. Het dollarteken fungeert als afsluiter van een record. Het geheel moet dus in een ASCII-tekst bestand staan, en als dit wordt geopend met Notepad moet het er als bovenstaand voorbeeld uitzien.
Een tagged bestand kan ook tags hebben van variabele lengte. Bijvoorbeeld:

In zo'n geval is het van groot belang dat een bijzonder teken wordt gebruikt tussen tag en inhoud. In het voorbeeld is dat het "pipe"-teken, “|”. Een spatie zou dan niet goed genoeg zijn, omdat een spatie ook als inhoud van de data kan voorkomen.
Voor zowel delimited als tagged bestanden dient u vast te stellen welke scheidingstekens er in gebruik zijn voor de verschillende records en velden. De importmodule wil van deze tekens de bijbehorende ascii waarden weten. Hierop gaan we op de volgende bladzijden in.
3.
“XML”
Beschrijvingen exporteren en importeren in het XML-formaat is een onderdeel van de standaardfaciliteiten voor data-export (AFO 132) en -import (AFO 131). Het is van toepassing op zowel bibliografische documenten als op authority records. Zowel export als import gebruiken de profielen die gecreëerd en gewijzigd worden via AFO 133, die op hun beurt optioneel gebruik maken van de conversieprofielen die worden beheerd via AFO 134. Dit alles houdt in dat XML-documenten worden geïmporteerd op identiek dezelfde manier als bijv. ISO2709, gescheiden of gelabelde beschrijvingen.
Als u databases beheert die gebaseerd zijn op één van de in de context van Vubis Smart meest gebruikte formaten (MARC21, UNIMARC and Smart), dan heeft u de volgende mogelijkheden:
·
Export en import van MarcXML-beschrijvingen.
-
Gebruik een import-/exportprofiel dat het MarcXML-formaat gebruikt.
·
Export en import van Dublin Core in XML-formaat.
-
Gebruik een import-/exportprofiel dat het Dublin Core-formaat gebruikt en gebruik als conversieprofiel één van de pregedefinieerde XML Dublin Core conversieprofielen.
·
Export en import van andere XML-formaten.
-
Hier zijn er meerdere mogelijkheden.
·
Creëer uw eigen conversieprofiel in AFO 134 en creëer een import-/exportprofiel in AFO 133 dat "XML Generiek" as bestandsformaat gebruikt. Als "recordscheider" vult u de naam in van het element dat de start van een nieuw record aangeeft.
·
Importeer/exporteer ISO 2709-beschrijvingen en gebruik een conversie-tool buiten Vubis Smart (u gebruikt dus een extern programma om de XML-beschrijvingen om te zetten naar het ISO2709-formaat).
·
Gebruik technieken buiten Vubis Smart om te converteren van of naar MarcXML of DC-XML. Standaard-technieken zoals XSLT kunnen worden gebruikt om dergelijke conversie uit te voeren.
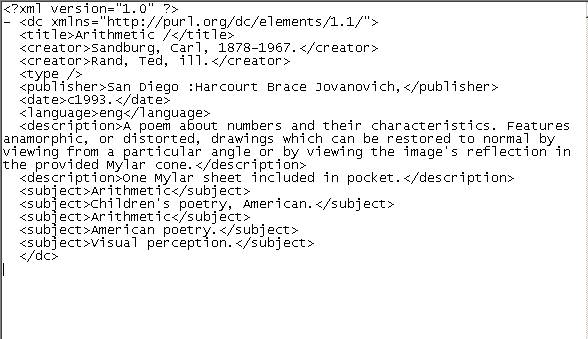
Een voorbeeld van Dublin Core XML:
Wanneer u AFO 133 start verschijnt een lijst met bestaande inleesprofielen. U kunt hier dubbelklikken op een bestaand profiel om dit te wijzigen of geheel nieuwe profielen aanmaken.
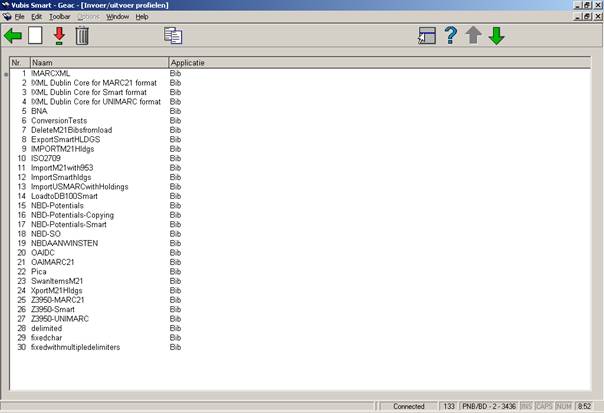
: klik op dit icoon om een nieuw profiel aan te maken. U krijgt eerst een invulscherm waar u de naam van het profiel moet ingeven en een applicatie kiezen (bibliografisch of authority).
: selecteer een bestaand profiel en klik op dit icoon om de gegevens te wijzigen.
: selecteer een bestaand profiel en klik op dit icoon om het profiel te verwijderen.
: selecteer een bestaand profiel en klik op dit icoon om een nieuw profiel aan te maken op basis van het bestaande profiel.
Nadat u een bestaand profiel heeft geselecteerd of een nieuw profiel heeft aangemaakt wordt een invulscherm met 5 tabbladen gepresenteerd. Al deze tabbladen dienen ingevuld te worden. Ze worden hieronder in detail beschreven.
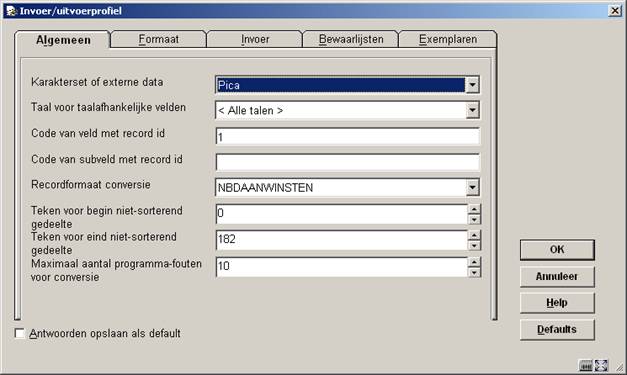
Het eerste tabblad behandelt de algemene gegevens van het te importeren bestand.
Karakterset van externe data: Hier dient u aan te geven uit wat voor karakterset de externe gegevens bestaan. Gebruik een van de voorgedefinieerde varianten. U kunt kiezen uit bijvoorbeeld ascii, ansi, iso (marc) of pica. Wanneer u niet zeker bent van het juiste type kunt u ook gewoon een instelling proberen. Tijdens de test-import ziet u vanzelf of er vreemde tekens verschijnen of diacrieten missen in de geïmporteerde gegevens. U dient dan een andere karakterset te kiezen.
Taal voor taal-afhankelijke velden: Als tweede kunt u een taal opgeven voor taal-afhankelijke velden. Vubis Smart kan rekening houden met het feit dat bepaalde velden alleen voor bepaalde talen van toepassing zijn. Dit kunt u dan hier instellen, afhankelijk van de te importeren gegevens. Doorgaans blijft dit veld op “alle talen” staan.
Code van veld met record ID: De code van veld met record id staat in dit geval op 1. Dit betekent dat de importmodule er nu van uitgaat dat het eerste veld een recordnummer bevat. In PICA bestanden is dit bijvoorbeeld het PPN-nummer. Intern kan het record-id gebruikt worden om bijvoorbeeld in een speciaal veld op te slaan (bijvoorbeeld het veld PPN-nummer). Aangezien Vubis Smart een eigen recordnummering heeft worden de oorspronkelijke record-id’s niet meer als zodanig gebruikt in Vubis Smart zelf.
Code van subveld met record ID: Bij code van subveld met record id kunt u eventueel nog specificeren dat het record niet in het hoofd- maar in een subveld daarvan staat.
Record formaat conversie: Recordformaat conversie is een van de belangrijkste instellingen van het inleesprofiel. Hier kiest u uit de lijst het conversieprofiel dat bij dit inleesprofiel hoort. Hiermee koppelt u dus het inlezen en converteren (AFO 133 en 134) aan elkaar. Omdat u meestal begint met het maken van een inleesprofiel en later pas met een conversieprofiel kunt u deze instelling eerst met rust laten.
Teken voor begin niet-sorterend gedeelte: De opties tekens voor begin en eind van het niet-sorterend gedeelte geven aan waar het sorteerteken in Vubis Smart moet komen te staan. Binnen Vubis heeft u de mogelijkheid om aan te geven dat bijvoorbeeld het begin van een titel niet gesorteerd dient te worden. Hiervoor gebruikt Vubis het Π (pi)-symbool. Wanneer de te importeren gegevens een ander teken gebruiken of op een andere manier deze informatie bevatten kunt u dit hier opgeven met een ascii waarde. PICA gebruikt bijvoorbeeld @ om dit gegeven aan te duiden, hiervoor vult u dus ascii waarde 182 in.
Teken voor eind niet-sorterend gedeelte: Zie boven.
Maximaal aantal programma-fouten voor conversie: Het maximale aantal fouten voor de conversie geeft aan hoeveel fouten er in de conversie mogen zitten voordat de conversie stopt. Hierbij wordt gekeken naar de geldigheid van gegevens, gebaseerd op de instellingen en veldregels in het formaat in AFO 151. Wanneer u daar bijvoorbeeld heeft ingesteld dat een taalaanduiding verplicht is, maar de te importeren gegevens bevatten geen taal, dan telt dit als een fout.
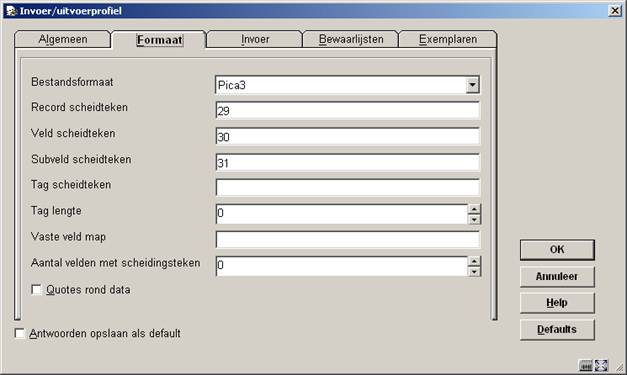
Het tweede tabblad geeft de mogelijkheid om het type bestand en de scheidingstekens in te voeren.
Bestandsformaat: Selecteer een formaat uit de dropdown lijst.
Record scheidteken: Bij record, veld en subveld-scheidingsteken geeft u de ascii waarden op van de scheidingstekens. Stel u exporteert een tekstbestand uit Excel om deze in te lezen in Vubis. U kiest dan in Excel al voor een scheidingsteken voor de velden, bijvoorbeeld puntkomma (ascii waarde 59) of tab (9). Aangezien Excel alle records op een eigen regel zet is de recordscheider van het resulterende tekstbestand 13,10 hetgeen een carriage return en line feed betekent (meerdere ascii waarden dienen gescheiden te worden door een komma).
Veld scheidteken: Zie boven.
Subveld scheidteken: Zie boven. Subvelden worden niet herkend in delimited bestanden.
Tag scheidteken: Zie boven. Wanneer u gebruik maakt van tagged gegevens en er staat bijvoorbeeld een spatie tussen ieder tagnummer en de gegevens dan voert u bij “tag scheidteken” ascii waarde 32 in.
Tag lengte: U geeft dan vervolgens ook de tag-lengte op (voor pica bijvoorbeeld 4, aangezien alle tags uit 4 cijfers bestaan).
Vaste veld map: De vaste veld map wordt alleen gebruikt wanneer alle gegevens op vaste posities in een bestand te vinden zijn.
Quotes rond data: Quotes rond data geeft aan of de importmodule de aanhalingstekens wel of niet moet meenemen als gegeven.
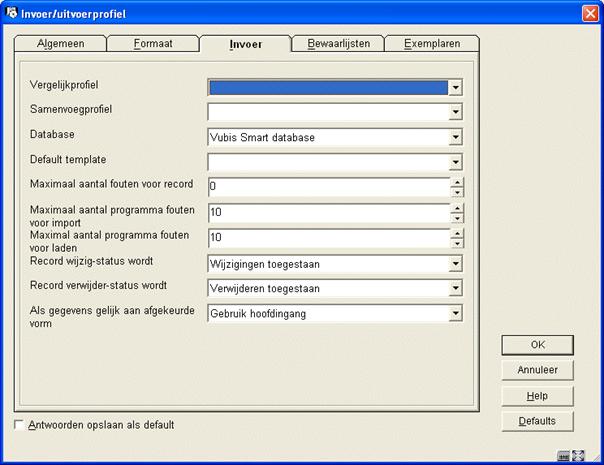
Het derde tabblad geeft u onder andere de mogelijkheid om een match- en merge-profiel op te geven.
Vergelijkprofiel: Selecteer een profiel uit de dropdown lijst. Met behulp hiervan kunt u aangeven wat er moet gebeuren met records die geladen worden, maar ook al in de database aanwezig zijn. Zo kunt u bijvoorbeeld aangeven dat het te importeren record altijd prevaleert, waardoor de bestaande overschreven wordt. Hiervoor dient u de betreffende matching en merging profielen zelf te hebben aangemaakt in AFO’s 114 en 115.
Samenvoegprofiel: Zie boven.
Database: Wanneer u over meerdere databases beschikt dient u aan te geven in welke database de gegevens geladen dienen te worden. Selecteer er een uit de dropdown lijst.
Default template: Selecteer er een uit de dropdown lijst (het sjabloon moet gedefinieerd zijn in
AFO 153, 154).
Maximum aantal fouten voor …: deze drie velden bepalen de fout tolerantie.
Record status: Als laatste kunt u statussen geven aan de nieuwe records.
Als gegevens gelijk aan afgekeurde vorm: Wanneer records geladen worden via AFO 131 is het mogelijk dat de inhoud van een onder authority control vallend bibliografisch veld overeenkomt met een bestaande afgekeurde vorm in de authority datatbase. Hier kunt u aangeven wat er in zo’n geval dient te gebeuren. Er kan uit drie verschillende opties worden gekozen indien de gegevens gelijk zijn aan de afgekeurde vorm:
· Maak nieuwe hoofdingang: De afgekeurde vorm wordt verwijderd uit de database en in plaats daarvan wordt een nieuwe hoofdingang aangemaakt.
· Neem gegevens niet op: De gegevens worden verwijderd uit het import reocrd – dit is de huidige situatie.
· Gebruik hoofdingang: Het veld wordt gekoppeld aan de hoofdingang van de afgekeurde vorm.
In alle drie de gevallen wordt een waarschuwing toegevoegd aan de rapportage van de import.
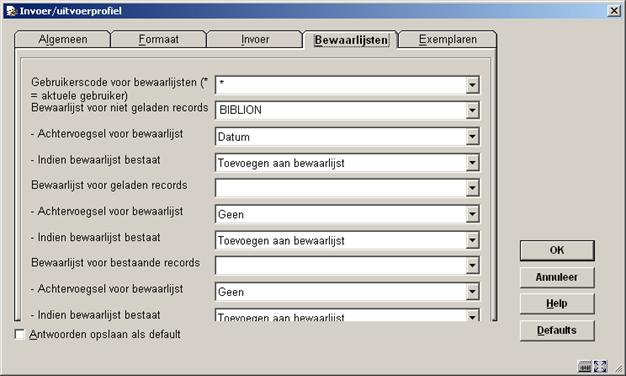
Het bewaarlijsten tabblad geeft u de mogelijkheid om bewaarlijsten aan te maken voor niet geladen records, nieuw geladen records en een lijst voor al bestaande records.
U kunt aangeven bij welke gebruiker deze lijst moet worden aangemaakt (* = huidige gebruiker), en of er een datum aan de naam van de lijst geplakt moet worden.

Op het laatste tabblad kunt u een bewaarlijst laten aanmaken voor titel-import waarbij objecten betrokken zijn. Door een termijn op te geven, een naam voor de bewaarlijst en aan te vinken dat deze lijst niet mag worden gewijzigd, kunt u op termijn de geladen objecten weer verwijderen uit het systeem. Deze opties zijn alleen geldig bij het importeren van gegevens. De laatste optie is alleen voor het exporteren; hierbij geeft u op van welke instellingen objecten bij de export betrokken mogen zijn.
Let op
Exemplaren worden geëxporteerd met een status (indien toegekend) als gedefinieerd in AFO 481 – Uitleen status codes – Tabblad Algemeen, onder Uitleestatus (extern).
· Document control - Change History
|
Version |
Date |
Change description |
Author |
|
1.0 |
unknown |
creation |
|
|
2.0 |
August 2006 |
updates for release 2.4.1 build 17 |
|